
可视化技术
可视化技术
1 | 一、01 Introduction 引言 |
Introduction 引言
可视化定义:基于计算机的可视化系统提供数据集的可视化表示,旨在帮助人们更有效地执行某些任务。三个标准:基于(非视觉)数据、生成图片、结果是可读和可识别的。
- 科学可视化:科学可视化的重点是使用计算机图形来创建视觉图像,这有助于理解复杂的,通常是大量的科学概念或结果的数值表示。应用领域:体积渲染(医学成像)、流(流体动力学)、连续数学:信号处理、流拓扑、网格划分… 真实地反映
- 信息可视化:信息可视化是通过使用交互式的视觉界面来交流抽象数据。与科学可视化相比,信息可视化更关注于抽象、高维的数据。应用领域:离散数学:统计、图论、组合数学… 创造性地反映
- 可视化分析:由可视交互界面为基础的分析推理科学。可视化分析将自动化分析技术与交互式可视化相结合,以便在非常大和复杂的数据集的基础上有效地理解、推理和决策。
Fundamentals of Data Visualizations 数据基础及基本数据可视化方法
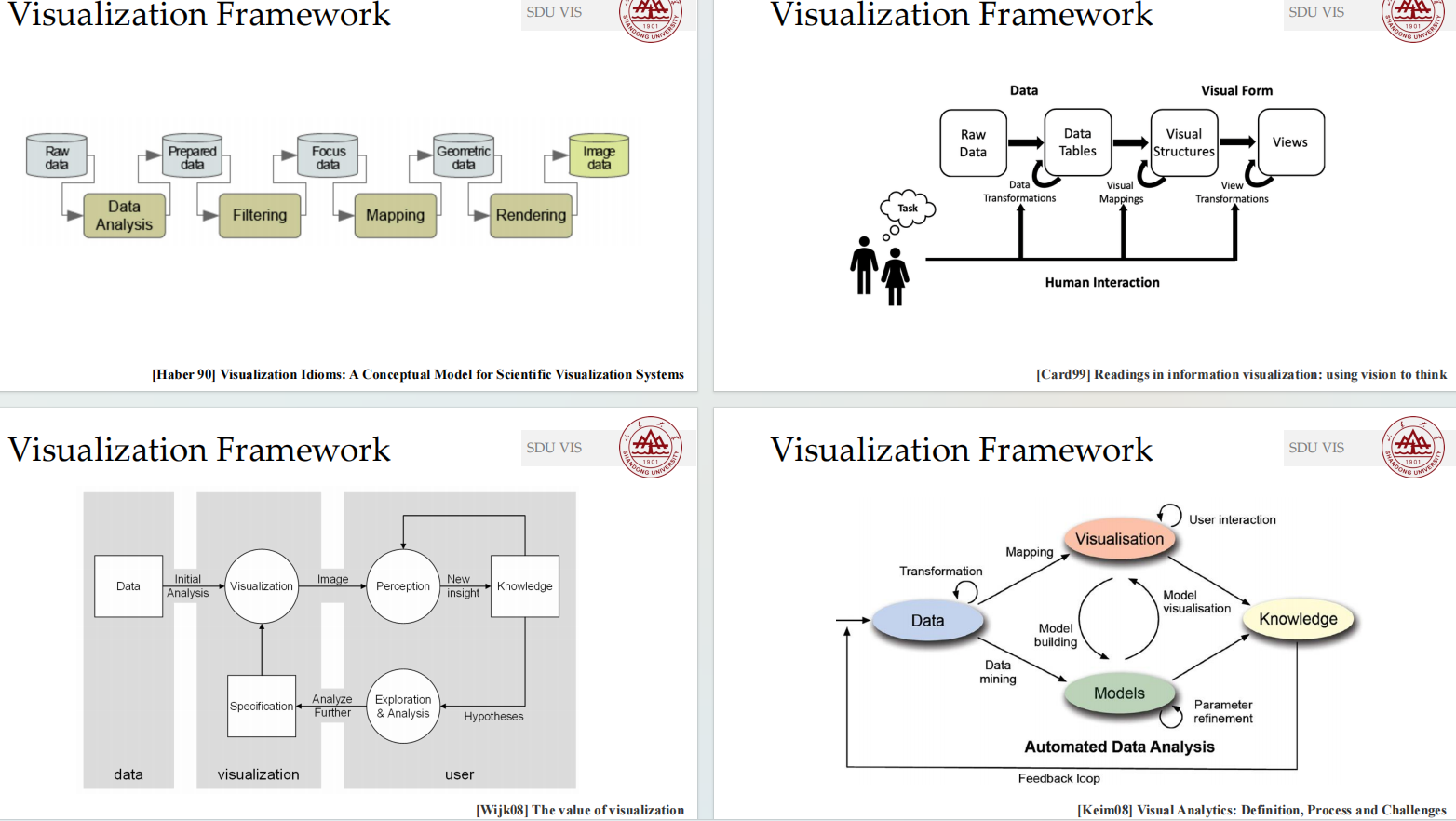
可视化的基本流程
Norminal,Ordered,Interval,Ratio
Boxplot 盒须图/箱线图
- 构建一个以Q1和Q3作为头和尾的箱子,在箱子内部用横线标上中位数。
- 计算fences(上下限),fence由1.5*IQR来决定,upper fences是在高于上四分位点1.5IQR的位置,lower fence是在低于下四分位点1.5IQR的位置。注意,fence只用于辅助构建箱型图,并不实际出现在箱型图中。
- 从第一步构建的箱子的两端画线到栅栏内最极端的数据值。
- 用特殊符号表示超出上下限的数据离群值,且有时使用不同的符号表示距离四分位数超过3个IQR的“远异常值”。
- 特点:可以反应原始数据分布的特征,即可以从图中看出上边缘、下边缘、中位数、两个四分位数以及离群点,能提供有关数据位置和分散情况的关键信息。
- 缺点:不能精确的衡量数据的偏态和尾重程度,对于较大的数据集不能很好的表示信息。
Visual Encodings 视觉编码
视觉图元:点线面
视觉通道:位置大小粗细
将不同的数据类型(Nominal,Ordinary,Quantity)分配给选定的图元类型中(point/bar/line…)的视觉通道(x,y,color,shape,size…)
1D:
- nominal名词属性
使用不同形状或大小或颜色一维的散点,聚合后可以使用柱状图、条形图、折线图来表示 - quantitative(单个点或是一系列点)
使用treemap或是使用不同大小或颜色的散点表示,聚合后可以用柱状图或不同大小的散点图(感觉折线图不行是因为聚合后是一个范围内的数量,折线图的一个维度只能表示一个点而不是范围)
2D:
- nominal x nominal
散点图,用不同的大小或者不同颜色或颜色深浅表示数量 - quantitative x quantitative
散点图,可以用颜色深浅和大小表示数量 - nominal x quantitative
散点图、柱状图,用不同颜色或大小或图标形状表示不同的类别(不同nominal)。也可以用tree map,用不同颜色表示不同类别nominal,用块大小表示数量
- 饼图——可以使用角度、颜色、高度、纹理来表示不同的变元
- 柱状图——使用stacked bar chart,其中每个柱状片段是一类数据,或者cluster bar chart。
- 散点图矩阵——每一个散点图表示的是高维变量中的某两个变量的可视化,每一个点表示一个数据点,对于单个散点图可以使用不同的颜色、大小、坐标轴表示不同的属性,最后将高维度数据中的两两变量的所有组合组成一个散点图矩阵。
- 平行坐标系——每列空间分配了一个变量,每个变量独立缩放到可用的垂直空间,对轴进行排序,每个数据案例都是一条折线,它在每一列的对应数据值处放置一个顶点,同一数据案例之间的顶点用线连接。
- 优点:
- 适用于分类问题和回归问题
- 一次可视化多达24个维度
- 平行坐标图可以突出显示单个数据,也可以绘制单个组,以比较该组与其余数据的特征
- 在处理数据集的子集时,平行坐标可以帮助将特定子集的特征与数据集的其余部分相关联
- 相邻的两个坐标轴正相关系数越大,在轴之间的一段折线越接近平行。负相关系数越大,线段之间的交叉越严重,甚至穿过两轴之间的一个点。一般情况线段有不同程度的交叉
- 比散点图更加容易找出属性之间的相关性。
- 缺点:
- 属性很多时需要大量的空间,整体呈现为一个长方形。
- 完整的绘制数据可能会导致数据堆积在一起,反而不能呈现更多的信息。在观察多变量数据的关系时可以添加数据选择的交互。
- 对坐标轴的表示范围和顺序非常敏感。
- 用户第一次使用难以直观的理解图标所表示的含义,需要显式的说明。所以通常作为数据可视化的一个选项,用于和其他的可视化图标做比对。
- 优点:
- 雷达图——每个数据样例使用一个雷达图表示,每个雷达图用延伸的不同方向表示不同属性,不同方向和中心点的距离表示数据的值。
视觉编码设计准则的可表达性(Expressiveness)和有效性(Effectiveness)
可表达性(Expressiveness):
视觉通道的可表达性主要研究某个视觉通道能够表达哪些数据类型。在表达数值类型的变量时主要使用的通道有:position, size, angle, slope, density等;表达类别类型的时主要使用的通道有:position, color hue(色相), 形状。
有效性(Effectiveness):
有效性是指一个给定的视觉通道能够在多大程度上代表某种类型的信息。
- 准确度
- 区分度
- 显著性 -前注意力机制
- 可分性
- 分组 -格式塔准则
Graphical Perception 图形感知
stevens 幂次法则
| 视觉通道 | 亮度 | 深度 | 面积 | 长度 | 饱和度 | 电流刺激 |
| 幂次 | 0.5 | 0.67 | 0.7 | 1.0 | 1.2 | 3.5 |
前注意力机制
格式塔准则:
- 相似原则Similarity
- 邻近原则Proximity
- 连通原则Connectedness
- 连续原则Continuity
- 对称原则Symmetry
- 闭合原则Closure
- Common Fate
- Transparency
- Past Experience
Color Computing 颜色计算
颜色感知与认知基本流程:光照 人类视觉系统响应 色彩的对立过程理论 色彩感知 色彩外观模型 色彩认知
颜色生成和颜色优化的区别:?
Visualization Evaluate 可视化评估
Edward Tufted的基本设计准则
- Graphical integrity 图形完整性
在图表上专注于要传递的信息,做到准确传递,不夸大或歪曲数据 - The lie factor 谎言因子
在图表中保持一个合适的lie factor,其中lie factor=以图形显示的效果大小 / 实际数据的效果大小,即图形在表达数据变化时的失真程度 - Maximize data-ink ratio 最大化data-ink比例
最大化data-ink的占比,data-ink占比 = data-ink / total ink in graphic,减少非必要的图形元素,使得数据更突出 - Avoid harmful chart junk 避免无效的图表垃圾
杜绝无用的可视化,即杜绝在可视化中出现让观看者从关键信息上分神的不必要可视化元素(可以使用适当的contextual representation来帮助可视化)
图表使用局限性
- 柱形图:需要数据有零值线
- 折线图:使用折线图主要比较的是数据的趋势或是线条与水平线的角度,对折线图尽量倾斜45°以减少视觉差异
- 饼图:
- 缺点:
- 人们对面积的感知不敏感,当两个切片占比相近时难以比较
- 当切片数量多的时候颜色混乱
- 饼图不能详细展现每部分的细节情况
- 依赖数据标签说明信息
- 适用类型:
- 适用于需要将部分与整体进行比较的、二维的、类别少的、占比区分度大的、对值进行排序、从12点钟方向、使用其他图形例如bar chart进行补充的数据可视化
- 缺点:
- 彩虹颜色表:
- 缺点:
- 人们对rainbow的颜色缺乏感知顺序,因为颜色不是自然有序的
- 人们通常把颜色分类,使用不同颜色来区分比较数据较难
- 人们对用颜色表示的极端数据缺乏感知
- 低亮度颜色(蓝色)可能会隐藏高频值
- 颜色过多时会导致可视化混乱
- 优点:
- 可以不同的明度来强调某些标量值
- 可以使用颜色进行类别表示
- 缺点:
- 3D图像:容易存在遮挡
- 文字表示需要清晰;避免使用深度的形式进行表示;使用外部认知,而不是内在认知(eyes beats memory)
Visualizing High-Dimentional Data 高维数据可视化
为什么要进行数据降维?可视化需要实现两个方面的功能,1.数据探索–确保您了解您的数据。2.数据交流–确保其他人理解您的见解或能够轻松地使用您的数据。而在高维数据中做到以上两点,解决方案就是进行数据降维。
MDS(Multi-Dimentional Scaling)多维尺度变换
- 基本原理:保持在降维后两点之间的距离与原来维度中的相似。具体来说,MDS算法首先计算原始数据点之间的距离,然后通过优化算法在低维空间中找到合适的投影,使得在低维空间中的距离与原始距离最接近。
- 优点:
- 不需要先验知识,计算简单
- 保留了数据在原始空间的相对关系,可视化效果比较好
- 缺点:
- 各个维度的地位相同,无法区分不同维度的重要性
- 不同的初始值可能导致结果不同,即陷入局部最优
- 存在拥挤问题
PCA(Principal Component Analysis)主成分分析
- 基本原理:找到能让数据降维后数据间的方差最大的轴,将数据线性的投影到该轴上,投影后的特征称为主成分。
- 优点:
- 使得数据集更易使用
- 降低算法的计算开销,速度快
- 去除噪声
- 使得结果容易理解,更加容易可视化
- 完全无参数限制。
- 缺点:
- 如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高
- 降维后数据的邻域点与原来空间中的邻域点可能不同
- 特征值分解有一些局限性,比如变换的矩阵必须是方阵
- 在非高斯分布情况下,PCA方法得出的主元可能并不是最优的
SNE(Stochastic Neighbor Embedding)随机近邻嵌入
- 基本原理:是通过仿射变换将数据点映射到概率分布上,主要包括两个步骤:
- SNE构建一个高维对象之间的概率分布,使得相似的对象有更高的概率被选择,而不相似的对象有较低的概率被选择。
- SNE在低维空间里在构建这些点的概率分布,使得这两个概率分布之间尽可能的相似。
t-SNE是在SNE的基础上进行了以下两点改进:使用对称SNE,简化梯度公式,优化了 p 和 q 的对称性;低维空间使用t分布取代高斯分布。
- 优点:
- 改变了MDS中基于距离不变的思想,将高维映射到低维的同时,尽量保证相互之间的分布概率不变,SNE将高维和低维中的样本分布都看作高斯分布,而t-sne将低维中的高斯分布改为T分布,这样做的好处是为了让概率小的簇之间距离拉大,从而解决了问题。
- t-SNE在使用时只需要稍微调整参数,就能在不同规模下展现高维数据点的聚类。
- 缺点:
- 主要用于可视化,很难用于其他目的。
- t-SNE倾向于保存局部特征,对于本征维数本身就很高的数据集,是不可能完整的映射到2-3维的空间
- t-SNE没有唯一最优解,且没有预估部分。
- 训练太慢。
- 惩罚的不同(对在高维数据中近的点到低维中远了的惩罚高,高维中远的到低维近的惩罚小)
联系和区别
PCA是线性降维,MDS是非线性的,PCA和MDS都是global,T-sne是非线性且local的方法。
global是将所有的点对之间的距离视为同等重要,local更加关注邻里之间的小距离
local mds改一下变sne
mds和sne都有拥塞问题
拥挤问题
拥挤问题就是说降维后各个簇聚集在一起,无法区分。比如有一种情况,高维度数据可以分开,降维到低维就分不开了,mds和sne都存在。
怎么解决:T-sne通过将sne中低维空间的高斯分布转换为t分布来解决
Tree Visualization 树可视化
两种表达方式:
- 节点连接式 Node-link
节点分布在空间中,用直线或曲线连接,用二维空间分割宽度和深度,空间用来表达等级取向- 优点:
- 能清楚地表达节点之间的关系
- 能表达深度层次结构
- 缺点
- 容易造成深度或宽度上的指数增长,难以充分利用空间结构
- 难以表达每个节点上的属性值
- 难以编码数据点中的更多变量
- 优点:
- 空间填充式 Enclosure
treemap是一种空间填充表示,每一项所占面积表示了节点大小,每个子树用一个矩形表示,该矩形被划分为与子树相对应的小矩形。对于每个孩子递归重复切片,将切片方向从垂直方向转换为水平方向或相反方向。可以使用区域对数据项的其他变量进行编码。- 优点:
- 提供整个树的单一视图更容易发现大/小节点
- 很好的表示节点链接之外的两个属性:color和area
- 节点多时可以较好的表示树的大小属性(值)和浅层次
- 树状图更适用于组级比较
- 缺点:
- 难以准确读取结构/深度
- border对于大的树的可视化会占用大量面积
- 难以找到好的纵横比
- 不好显示除父子关系之外的链接
- 不支持单个项目的可视化搜索
- 人们对treemap所使用的面积形式通常难以比较大小
- 应用:可以用在文件目录结构、软件图表、篮球统计数据、大小查询的地方
- 优点:
节点连接的Tidy layout树布局思想 ?
Graph Visualization 图可视化
力导向模型(Force-directed model)
- 伪代码:
1
2
3
4
5
6
7
8初始化点的位置
repeat 直到收敛:
for 每个节点 v:
计算来自所有其他节点的斥力
for 节点 v 的每个邻居节点:
计算 u,v 之间的引力
计算作用于节点 v 上的合力
根据合力更新节点 v 的位置 - 基本思想:开始把节点的位置随机初始化,我们把节点想象为物理粒子,这个粒子有引力和斥力,引力就是边的作用,斥力是所有粒子之间的作用,在粒子间斥力和引力的不断作用下,粒子们从随机无序的初态不断发生位移,逐渐趋于平衡有序的终态。
- 优点:
- 可以将有连边的节点画得相对靠近,但又不至于太近
- 缺点:
运行时间长,很难收敛,也容易出现交叉和节点的重叠- 算法时间复杂度高(,n是节点数量),计算斥力复杂()
- 对很大的图进行力导向图算法的时候可视化效果差
- 应用算法时难以选择合适的迭代步长
- 算法收敛后多个点可能重合
- 使用不同的参数和初始化可能收敛到同一张图
- 改进:
使用kdtree 四叉树 八叉树加速搜索- 使用距离的平方和进行比较、计算,避免开方计算
- 排斥力计算的时间复杂度过高(),使用Barnes-Hut算法通过聚合粒子来估算粒子之间相互的斥力,具体使用四叉树实现,最后优化的算法复杂度为(每一个非叶节点表示一组相近的物体。如果一个非叶子节点的质心离某个物体足够远,那么就将树中那个部分所包含的物体近似看成一个整体,其位置就是整组物体的质心,其质量就是整组物体的总质量。如果非叶子节点离某个物体并不足够远,那么就递归地遍历其所有子树。)
- GEM算法通过减少一个temperature参数来允许点在迭代早期移动大的距离后期移动小的距离来加速
- 在两个节点之间距离为0(过近)的时候随即产生一个小力将二者分开防止当二者有相同邻居时会一直贴合在一起
- 可以将距离为n条边的节点之间建模为长度为nL的弹簧q
- 增加一个参数来控制引力和斥力之间的比重
- 随机节点采样RVS
Stress Model
Text Visualization 文本数据可视化
文本可视化流程:文本数据获取、分词 文本数据特征提取 文本数据结果呈现
文本可视化方式
- 词云(tag cloud),基于word count
- 词树(word tree),基于单词序列
- 短语网(phrase net),基于查找特殊的单词连接模式:‘A and B’,‘A at B’,‘A of B’,etc
Scalar Field Visualization 标量场数据可视化
间接体绘制
- marching squares算法
- marching cubes算法
- 从原始数据中构造六面体以及六面体信息(如顶点值、坐标值)
- 逐个遍历六面体,查找对应的顶点状态信息获取交点
- 利用线性插值方法计算各棱边上交点的位置并且连接三角面片
直接体绘制
- 光线投射算法(Raycasting)
- 从图像中的每一个像素点沿固定方向投射一条光线。
- 光线穿过物体并沿着光线采样,通过插值获得采样点的密度值。
- 根据传输函数计算颜色以及透明度。
- 依据光线发射-吸收模型对颜色值进行累加,直至遍历光线所有样本点,得到相应像素颜色及透明度数值。
Interaction 交互
交互式可视化的意义:互动以最大化认知。能够针对任何用户的操作提供快速、可逆、可持续的反馈;用户可以首先获得一个概述,之后使用交互按需提供细节;
缩放Zooming:几何缩放(对图片放大缩小),语义缩放(显示的细节也跟着放大缩小)
动态查询dynamic query
- 是什么?是对象和动作的可视化表示,是快速渐进和可逆的动作,能立即和连续的显示结果,并且是通过指向选择无需打字。
- 与普通SQL查询有什么不同?
SQL查询:
- 面向程序员
- 严格的语法
- 只显示精确的匹配项
- 太少或太多的点击次数
- 没有关于如何重写查询格式的提示
- 低效率,查询和返回结果都很慢
- 结果以表的形式返回
- 动态查询优点:快速、简便、可逆、可以消除杂乱、可以看到样例的出现和消失。
- 动态查询缺点:无法进行布尔查询、过滤器占用空间、当数据集变大时查询变慢
brush and linking:与多个视图一起使用,在一个视图中选择/突出显示案例会在所有其他视图中突出显示案例,并且将鼠标移到案例上可以揭示关系模式。
brush:选择一个数据子集
link:选择的元素必须通过元组(匹配数据点)或查询(匹配范围或值)进行链接
参考资料
https://blog.csdn.net/m0_51525731/article/details/126935753?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170391104916800180639543%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=170391104916800180639543&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-126935753-null-null.142^v99^pc_search_result_base8&utm_term=%E5%B1%B1%E4%B8%9C%E5%A4%A7%E5%AD%A6%20%E5%8F%AF%E8%A7%86%E5%8C%96&spm=1018.2226.3001.4187
https://blog.csdn.net/sinat_34550050/article/details/112973646?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%B1%B1%E4%B8%9C%E5%A4%A7%E5%AD%A6%20%E5%8F%AF%E8%A7%86%E5%8C%96&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-3-112973646.142^v99^pc_search_result_base8&spm=1018.2226.3001.4187
https://zhuanlan.zhihu.com/p/151393730