
神经网络与深度学习
神经网络与深度学习
软院复习笔记 软院期末 没找到计科的
课件和视频-台大李宏毅
Regression 回归
预测 中的参数
什么是好的 ?使得均方误差损失函数 最小的 。
目标转化为求 。方法:Gradient Decent梯度下降
梯度下降:
- 选择初值
- 计算梯度 ,
- 迭代, 以此类推可得
过拟合:过拟合是指相较有限的数据而言,模型参数过多或者结构过于复杂,且过于紧密或精确地匹配特定数据集,以致于无法良好地拟合其他数据或预测未来的观察结果的现象。(更复杂的模型在测试集上不一定能带来更好的效果)
正则化:。 越小意味着模型越平滑(smooth)。越大,正则项的惩罚效果就越强,正则化的约束就越强,模型的复杂度就越低,就越不考虑在训练集上的误差,越不容易过拟合。但容易欠拟合。
Gradient Decent 梯度下降
矩阵形式

Adagrad:根据自变量在每个维度的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应所有维度的问题。如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素的学习率将下降较快;反之,如果目标函数有关自变量中某个元素的偏导数一直都较小,那么该元素的学习率将下降较慢。
(是一个参数,,,)
Stochastic Gradient Decent:随机梯度下降,加快训练过程,在每次更新时用一个样本来调整参数 。
Feature Scaling:特征缩放,将数据的不同变量或特征的范围进行标准化,e.g. 。
Bias and Variance 偏差与方差
偏差和方差,是error的来源。
数据的均值、方差及其期望。
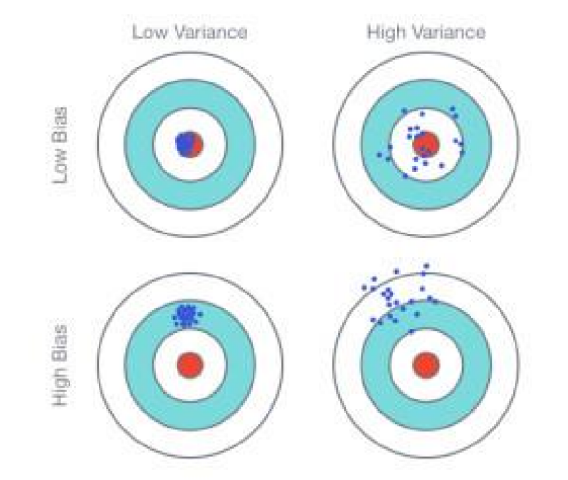
若模型在训练集上表现很差,意味着有较大的bias(欠拟合);若模型在训练集上表现较好,但在测试集上表现较差,意味着有较大的variance(过拟合)。对于较大的bias,应当使用较复杂的模型;对于较大的variance,应当使用更多训练数据或使用正则化。
模型选择:在bias和variance之间做权衡 N折交叉验证。
Deep Learning 深度学习
神经网络 与 深度学习
激活函数:sigmoid函数
神经网络前馈过程的计算
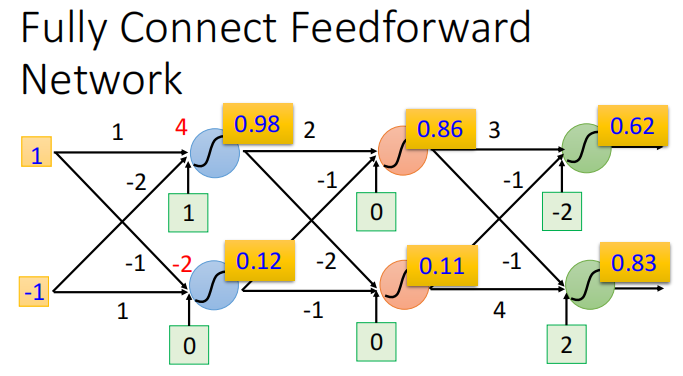
矩阵形式
Backpropagation 反向传播
反向传播:更高效地计算梯度,用于梯度下降
应用链式法则(chain rule)。从后往前计算
Youtube讲解视频 知乎解析
Logistic Regression 逻辑回归
逻辑回归
- model:
- loss function:
- 目标: 其中
令 for class1, for class2,可得
-
cross entropy
-
通过梯度下降确定 ,要计算梯度 。经计算可得 ,根据梯度下降的参数更新公式,可得 。(compare to linear regression)
Generative vs Discriminative
以上通过梯度下降得到的 属于Discriminative,通过找到 来计算 属于Generative。()
Discriminative的准确率会更高,但当训练数据较小,噪声较多,Prior和class-dependent probability有不同的来源时,Generative会更好。
Multi-class Classification
通过softmax层,将每个类别的结果通过 放大,然后规范化到(0,1)之间,且。然后要最小化cross entropy: 。其中,当 class i,那么 ,否则
逻辑回归的局限性:无法处理线性不可分的情况,因此,我们需要通过Feature Transformation将样本映射到其他空间上。如何Feature Transformation?可以通过逻辑回归的model function:,一个function可以称作一个Neural,许多Neural组成的网络称作Neural Network。
Text Classification 文本分类
CNN图片分类
- CNN(Convolutional Neural Network 卷积神经网络)相较于DNN(Deep Neural Network 深度神经网络)简化了参数
- 最基本的多层CNN图片分类网络结构:image Convolution Max Pooling Convolution Max Pooling Flatten Fully Connected Feedforward Network
- Convolution:用filter在image中做矩阵内积,得到feature map。
- Max Pooling:将feature map分成一些区域,取区域内的最大值,使得维度进一步缩小。
- Flatten:将得到的矩阵展开成 的向量,作为全连接层的输入。
TextCNN:将word转化为向量,那么一个句子就是一个矩阵,可以作为CNN的输入,实现文本分类。
RNN:Recurrent Neural Network 循环神经网络,将会记忆隐藏层的输出,在下一次进入隐藏层时,将之前记忆的输出作为输入,影响着这次的输出(另外一种是记忆整个网络的输出)。因此输入的顺序将会影响最终的结果。
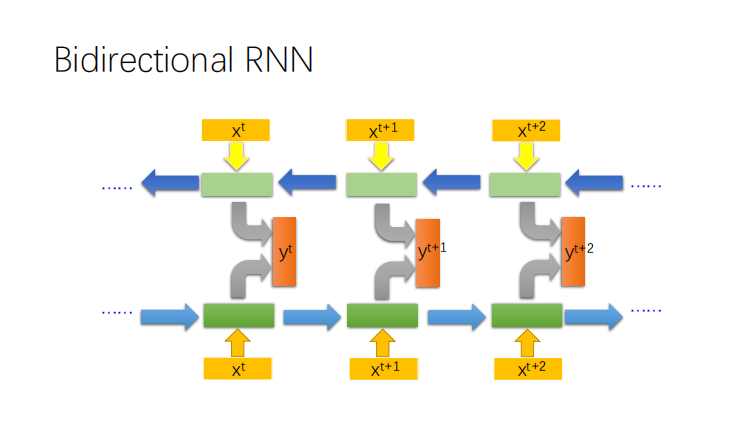
Bidirectional RNN:双向循环神经网络。记忆模块会考虑本次输入之前的信息,反向的RNN使得记忆模块能够考虑本次输入之后的信息,将两个网络的输出综合起来,使得整个网络的表现更好。
LSTM:Long short-term Memory 长短期记忆,知乎解析。
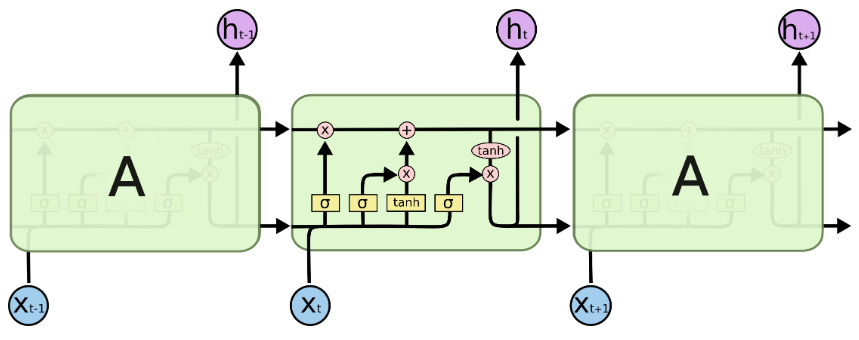
遗忘门 输入门 输出门 计算公式
LSTM的参数是SimpleRNN的4倍,参数数量
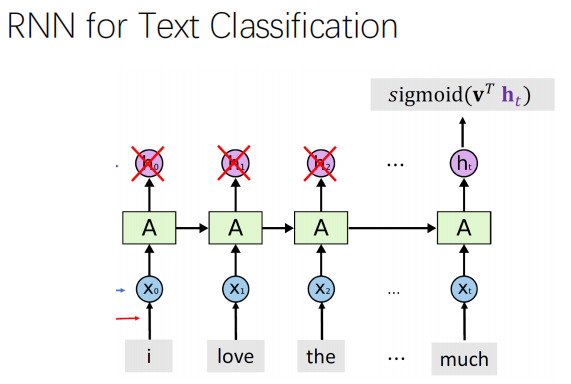
RNN for Text Classification
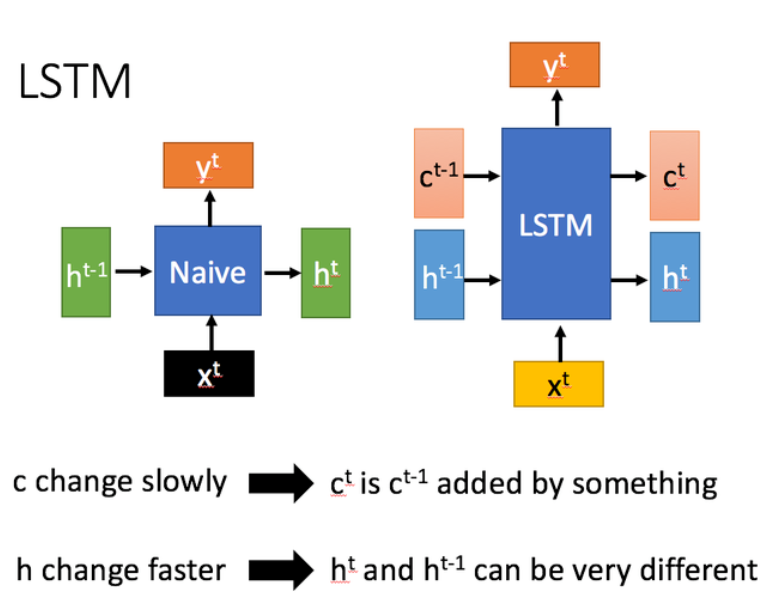
LSTM vs Naive RNN:RNN只有一个传输状态 ,LSTM有两个传输状态
Text Generation
Attention:Attention机制是从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多数不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
Pointer:Pointer Network是一种对attention机制的应用。在summary任务中,对于词典中不存在的词(人名、地名),通过copy输入中的这些词来得到输出。
Self-Attention:计算过程与Attention一样,但Q K V三者都来源于X。Youtube讲解视频 知乎解析
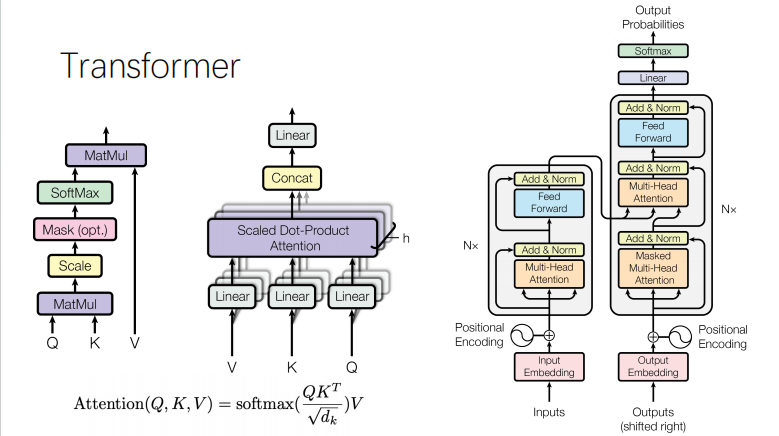
Transformer:Youtube讲解视频(同上) 知乎解析
参考资料
https://blog.csdn.net/m2607219640/article/details/131080808?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%B1%B1%E4%B8%9C%E5%A4%A7%E5%AD%A6%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-131080808.142^v99^pc_search_result_base8&spm=1018.2226.3001.4187
https://blog.csdn.net/horsetaill/article/details/131112733?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170391052116800188583833%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=170391052116800188583833&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-4-131112733-null-null.142^v99^pc_search_result_base8&utm_term=%E5%B1%B1%E4%B8%9C%E5%A4%A7%E5%AD%A6%20%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0&spm=1018.2226.3001.4187
https://speech.ee.ntu.edu.tw/~hylee/ml/2016-fall.php
https://www.youtube.com/watch?v=ibJpTrp5mcE
https://zhuanlan.zhihu.com/p/40378224
https://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/Logistic%20Regression%20(v3).pdf
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://zhuanlan.zhihu.com/p/32085405
https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=61
https://zhuanlan.zhihu.com/p/609523552
https://zhuanlan.zhihu.com/p/338817680