
信息检索与数据挖掘
信息检索与数据挖掘
Information Retrieval 信息检索
Inverted Index 倒排索引:每个词项都有一个记录出现该词项的所有文档的列表,该表中每个元素记录的是词项在某文档中的一次出现信息(通常包括词项在文档中出现的位置)这个表中的每个元素通常称为倒排记录(posting)。每个词项对应的整个表(一行)称为倒排记录表(posting list)。所有词项的倒排记录表一起构成全体倒排记录表(postings)。
建立过程:
- 收集需要建立索引的文档。
- 将每篇文档转换成一个个词条(token)的列表。(tokenization)
- 进行语言学预处理,产生归一化的词条作为词项。
- 对所有文档按照其中出现的词项来建立倒排索引,索引中包括一部词典和一个全体倒排索引表。
布尔查询:
- AND:选择两个posting list,合并。时间复杂度
1
2
3
4
5
6
7
8
9
10
11INTERSECT(p1, p2)
answer <- []
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
then ADD(answer, docID(p1))
p1 <- next(p1)
p2 <- next(p2)
else if docID(p1) < docID(p2)
then p1 <- next(p1)
else p2 <- next(p2)
return answer - OR
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19UNION(p1, p2)
answer <- []
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
then ADD(answer, docID(p1))
p1 <- next(p1)
p2 <- next(p2)
else if docID(p1) < docID(p2)
then ADD(answer, docID(p1))
p1 <- next(p1)
else ADD(answer, docID(p2))
p2 <- next(p2)
while p1 != NIL
do ADD(answer, docID(p1))
p1 <- next(p1)
while p2 != NIL
do ADD(answer, docID(p2))
p2 <- next(p2)
return answer - NOT
- AND NOT
1
2
3
4
5
6
7
8
9
10
11
12
13
14AND_NOT(p1, p2)
answer <- []
while p1 != NIL and p2 != NIL
do if docID(p1) = docID(p2)
then p1 <- next(p1)
p2 <- next(p2)
else if docID(p1) < docID(p2)
then ADD(answer, docID(p1))
p1 <- next(p1)
else p2 <- next(p2)
while p1 != NIL
do ADD(answer, docID(p1))
p1 <- next(p1)
return answer
查询优化:OR:先短后长;AND:先短后长
字典数据结构:
- 哈希表
- 优点:查询较快,时间复杂度
- 缺点:
- 寻找原词的变体较困难;
- 不能进行前缀搜索/tolerant retrieval;
- 如果词汇数量不断增长,就需要偶尔进行昂贵的重新整理操作。
- 树:二叉树(最简单),B树(最常用),B+树
- 优点:可以进行前缀搜索
- 缺点:
- 查询速度慢,时间复杂度 (平衡树);
- 重新平衡二叉树操作代价昂贵(B树缓解了这一问题)
Biword Index:将连续两个词看成一个item,进行长短语查询时可以分解成上述item然后进行and的布尔查询。
- 缺点:
- 存在false positive,即符合布尔查询条件但不存在该短语
- 倒排索引表太大
- 不适用于单词查询
双字索引不是标准的解决方案(对于所有的双字),但可以是复合策略的一部分
Positional Index:在倒排索引表中docID后加上单词的出现位置。可以用于Proximity queries(邻近查询)
Skip Pointers:在posting中设置skip pointer,可以跳过那些必然不在结果中的docID,只适用于AND操作。原本的倒排记录表合并算法需要 ,但是如果使用了跳表,则可以达到次线性时间。通常,每 处均匀放置跳表指针,p为倒排记录表的长度。
Tolerant Retrieval 容错式检索
Wild-card queries 通配符查询:
B树可以解决’‘类查询,逆B树可以解决’‘类查询,两者求交集可以解决’'类问题。操作代价昂贵,故使用轮排索引。
轮排索引:
引入符号$表示字符结束位置,并将词项旋转得到轮排词汇表。对于单词,拓展成:,,,,,。
对于查询 ,查找 ,对于查询 ,查找 (查询最后+$,再旋转使得查询以结尾)
轮排索引查询过程:
- 向右旋转查询通配符
- 使用B树查找
Bigram(k-gram) index:用$标志词项开始和结束,k-gram索引结构中,其词典由词汇表中所有词项的所有k-gram形式构成,倒排记录表则由包含该k-gram的词项组成。
例如: 的3-gram形式为,,,,。倒排记录表的形式如下:
Bigram(k-gram) index 查询过程:将通配符查询分解为k-gram的形式并用AND连接,进行布尔查询,查询的结果中会出现false positive,所以必须要进行过滤。最后将剩余的结果在词项-文档倒排索引中查询文档。
- 优点:快,空间利用高效(相对于轮排索引)
Spelling correction 拼写校正
- 词项独立校正
- 编辑距离
- k-gram重合度
- 使用k-gram索引返回与查询词q具有很多(超过某阈值的)公共k-gram的词项。并采用Jaccard系数进行修正(Jaccard系数 ),其中A、B分别是查询q和词项的k-gram集合,仅当Jaccard系数超过设定阈值时,才将对应词项保留。在计算Jaccard系数时需要知道查询q和词项t的k-gram集合,查询q已知,但倒排记录中可能并不包含完整的t字符串,而是t的某种编码形式,那么t的k-gram集合不易知道。但在单边扫描、合并的过程中已经可以得知匹配上的k-gram个数,即分子。同时,只要知道t的长度,再加上已知q的长度,那么由长度可以计算得到q和t分别的k-gram个数,减去匹配上的k-gram个数,即为k-gram的并集个数,即分母。
- 上下文敏感校正:对查询中每个单词查找可能的拼写正确词,考虑文档集合或查询日志中高频的组合结果
Index Construction 索引构建
硬件基础
- 访问内存比访问磁盘速度快得多。因此要尽可能把数据放在内存中,尤其是频繁访问的数据(缓存技术 caching)
- 在磁盘读写时,磁头移到数据所在磁道需要时间,称为寻道时间。为使数据传输率大,连续读取的数据块在磁盘上应连续存放
- 操作系统往往以数据块为单位读写(缓冲区)
- 数据从磁盘传输到内存是由系统总线而不是处理器实现,因此磁盘I/O时处理器仍可以处理数据,可以利用这一点对数据进行压缩后传输
索引方法:
- 基于块的排序索引算法(BSBI)
- 由于内存不足,需要使用基于磁盘的外部排序算法,核心要求是在排序时尽量减少磁盘随机寻道的次数。
- 算法流程
-
将文档集分割成几个大小相等的部分
-
将每个部分的词项ID-文档ID对 排序
-
将中间产生的临时排序结果存放到磁盘中
-
将所有的中间文件合并成最终的索引
将文档解析成(词项ID-文档ID)对,直到放满一个块的空间(ParseNextBlock函数),将其在内存中快速排序,将排序的块转换成倒排索引存入磁盘,所有块都处理完后,将每个块对应的索引文件合并成一个索引文件(维护读缓冲区和写缓冲区,使用优先队列选择最小的未处理词项ID进行处理,合并结果写回磁盘)。
1
2
3
4
5
6
7
8BSBIndexConstruction()
n <- 0
while (all documents have not been processed)
do n <- n+1
block <- ParseNextBlock()
BSBI-Invert(block)
WriteBlockToDisk(block, fn)
MergeBlocks(f1, ... , fn; fmerged)
-
- 该算法主要时间消耗在排序上,时间复杂度为 ,其中T是词项ID-文档ID对的个数。而在实际索引构建中,时间往往取决于文档分析(ParseNextBlock)和最后合并(MergeBlocks)的时间。
- 优缺点:基于块的方法可扩展性好,但需要一种将词项映射成词项ID的数据结构,对于大规模文档,此数据结构往往很大以致难以在内存中存放。
- 内存式单遍扫描索引方法(SPIMI)
- 算法流程
- 算法逐一处理每个词项-文档ID,若词项是第一次出现,则将其加入词典(最好通过哈希表实现),同时建立一个新的倒排记录表;若该词项不是第一次出现,则直接返回其倒排记录表。(注意:这里倒排记录表都是在内存中的)
- 向上面得到的倒排记录表增加新的文档ID。(注意:不同于BSBI,这里并没有对词项ID-文档ID排序)
- 内存耗尽时,对词项进行排序,并将包含词典和倒排记录表的块索引写入磁盘。这里,排序的目的是方便以后对块进行合并。
- 重新采用新的词典,重复以上过程。最后,将多个块合并成最后的倒排索引
- 算法的时间复杂度为 ,因为它不需要对词项-文档ID对进行排序操作,所有操作最多和文档集大小呈线性关系。
- 优缺点:
- 更具扩展性
- 只要硬盘空间足够大,SPIMI就能够索引任何大小的文档集
- 由于不需要排序操作,因此处理的速度更快
- 由于保留了倒排记录表对词项的归属关系,因此能够节省内存,词项的ID也不需要保存
- 压缩功能会使SPIMI更加有效。(压缩词项、压缩倒排记录表)
- 算法流程
两者区别
BSBI一开始就整理出所有词项ID-文档ID并对它们进行排序,SPIMI直接在倒排记录表中增加一项,每个倒排记录表是动态增长的(也就是说,倒排记录表的大小会不断调整),同时立即就可以实现全体倒排记录表的收集。这样做速度快并且能节省内存。
- 分布式索引构建方法
-
MapReduce
- map阶段将输入的数据片映射成键-值对。这个map阶段对应于BSBI和SPIMI算法中的分析任务,因此也将执行map过程的机器称为分析器(parser)
- reduce阶段,我们想将同一键(词项ID)的所有值(文档ID)集中存储以便快速读取和处理。给定一个键(词项ID),将所有值(文档ID)汇总并组织成倒排表的过程由reduce阶段的倒排器(inverter)来完成

-
Scoring, Term Weighting and the Vector Space Model 文档评分、词项权重计算以及向量空间模型
Bag of words 词袋模型:不考虑词在文档中出现的顺序
用词项频率衡量查询q和文档d的相关性
词项频率 Term frequency tf:词项t在文档d中出现的次数,记为
。由于相关性并不正比于词项频率tf,所以引入对数词频
文档-查询的相关性得分可以表示成所有同时出现在q和d中的词项的词频的对数之和
文档频率 Document frequency df:出现词项t的文档数目,记为
逆文档频率 Inverse document frequency idf:
词频-逆文档频率 tf-idf:。tf-idf值随着词项在单个文档中出现次数(tf)增加而增大,随着词项在文档集中数目(df)增加而减小。
对于含有两个以上查询词的query,idf才会影响排序结果,对于只有一个查询词的query,idf对排序结果没有影响,因为idf相当于这个词的权重。
Query的最终文档排序:
向量空间模型
每篇文档表示成一个基于tf-idf权重的实值向量。(是词项集合,表示词项个数),于是,有一个维实向量空间
- 空间的每一维都对应一个词项
- 文档是空间中的点或者向量
- 维度非常高:特别是互联网搜索引擎,空间可能达到千万维或更高
- 向量空间非常稀疏:对每个文档向量来说大部分都是0
对于查询query做同样的处理,即将查询q表示成同一高维空间的向量
在向量空间内根据query与文档的向量间的距离来排序
欧几里得距离不可取,因为它对向量长度很敏感,而长文档不一定更相关。故选择计算query与文档的向量间夹角代替距离。
长度归一化:可以用L2范数对文档长度进行归一化 。一个文档向量除以它的L2范数就是给这个文档进行了长度归一化,消除长度差异带来的影响。

tf-idf 权重机制的变形

向量空间模型小结
- 将query看作带tf-idf权重的向量
- 将每个文档也看作带tf-idf权重的向量
- 计算query向量与每个文档向量间的余弦相似度
- 根据相似度大小将文档排序
- 将top K个结果返回给用户
Information Retrieval: Evaluation 信息检索:评价
Precision and Recall 查准率和召回率
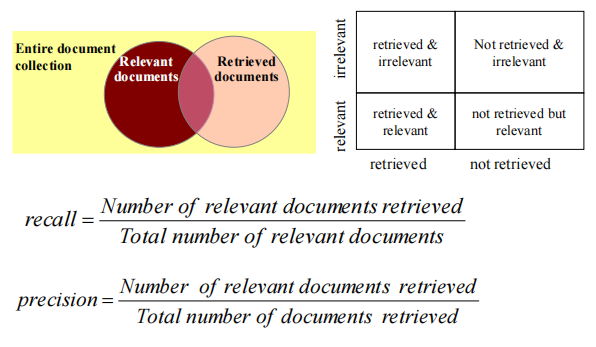
为什么不用accuracy准确度

F-measure:, 得 。
Rank-Based Measures
- Binary relevance
- Precision@K (P@K)
- 前k个结果中,正确的占比
- Mean Average Precision (MAP) 平均精度
- 每次查询,记前n项中相关文档的位置K1 … Kr,求P@K1 … P@Kr的总和除以总相关文档数量(),作为单次查询的分数,再求每次查询的分数的均值。
- Mean Reciprocal Rank (MRR) 平均倒数排名
- 只考虑查找到的第一个相关文档的位置,取倒数,作为单次查询的分数,再求每次查询的分数的均值。
- Precision@K (P@K)
- Multiple levels of relevance
- Normalized Discounted Cumulative Gain (NDCG) 归一化折损累计增益
- CG 累计增益:
- DCG 折损累计增益:
- IDCG 理想折损累计增益:理想情况下的最大DCG值
- NDCG 归一化折损累计增益:
- Normalized Discounted Cumulative Gain (NDCG) 归一化折损累计增益
Probabilistic Information Retrieval 概率信息检索
贝叶斯定理:
优势率(odds):
概率排序原理PRP:PRP希望可以按照值的降序来排列所有文档。
二值独立模型BIM:引入了一些简单假设,简化对概率函数的估计。二值指的是布尔值:文档和查询都表示为词项出现与否的布尔向量。独立指词项在文档中的出现是相互独立的。
- 排序函数的推导。得到最后用于排序的量RSV(retrieval status value 检索状态值):
- 如何估算:
- 的估算:假设相关文档S只占所有文档的极小一部分,那么可
通过整个文档集的统计数字来计算与不相关文档有关的量。 - 的估算
- 的估算:假设相关文档S只占所有文档的极小一部分,那么可
BM25:重视词项频率和文档长度。
其中 是词项 在文档 中的权重, 和 分别是文档d的长度及整个文档集中文档的平均长度。 是一个取正值的调优参数,用于对文档中的词项频率进行缩放控制。如果 取 0,则对应BIM模型;如果 取较大的值,那么对应于使用原始词项频率。 是另外一个调节参数 (),决定文档长度的缩放程度: 表示基于文档长度对词项权重进行完全的缩放, 表示归一化时不考虑文档长度因素。
和vector space model相比有什么优势?两者都考虑了tf、idf、文档长度,但BM25引入了超参数,可以调整超参数适应不同的系统、任务、数据集,效果会更好,但vector space model无法调整。
Language Models for IR 基于语言模型的信息检索模型
语言模型:一个语言模型(LM)是从某词汇表上抽取的字符串到概率的一个映射函数。
查询似然模型:在这个模型中,我们对文档集中的每篇文档构建其对应的语言模型。目标是将文档按照其与查询相关的似然排序。依据贝叶斯公式,有
- 对所有文档都一样,可以忽略
- 文档先验概率往往可以视为均匀分布,因此也可以忽略。
- 最后按照进行排序:这是文档d对应的语言模型生成q的概率
最普遍的计算P(q|d)方法:使用多项式一元语言模型(等价于多项式朴素贝叶斯模型):,其中, 是查询q的多项式系数,对于某个特定的查询,它是一个常数,因此可以被忽略。
查询生成概率的估计:在MLE(最大似然估计)和一元语言模型假设的情况下,给定文档d的LM 生成查询q的概率为:
实际上就是q中的每个词在文档中出现的频率相乘,如果q中有个词在文档中没有出现(很有可能发生的事情),那频率就为0,整体算出来的概率就为0,这是一个非常严格的“与”语义:所有查询项都出现在文档中的时候才有一个非零的概率。另外,只出现一次的词会被过度估计,这是因为他们仅有一次出现一定程度上处于偶然性。
平滑:
-
Jelinek-Mercer smoothing
- ,其中 , 是基于全部文档集构造的LM。上述公式使用了线性插值
-
Dirichlet smoothing
JM smoothing适用于关键词查询,Dirichlet smoothing适用于长查询;两者都对平滑参数敏感,需要调整好参数。
Vector space vs BM25 vs LM
- BM25/LM基于概率,vector space基于相似度,几何或线性概念
- 词项频率tf在三个模型中都有用到
- LM直接使用tf,BM25/vector space:经过处理后使用
- 长度归一化
- vector space:cosine规范化或pivot(枢轴)规范化
- LM:概率本来就是长度规范化的
- BM25:调整参数来最优化长度规范化
- 逆文档频率idf
- BM25/vector space 直接使用
- LM:结合了词项频率tf和文档集频率cf,起到与idf相似的作用
Link Analysis 链接分析
Web图:网页视为节点,超链接视为有向边,可以将网络看成一张有向图。可以通过链接结构对网页进行排序(PageRank)。
PageRank:定义网页j的rank , 由指向它的节点i的rank除以节点i的出度再求和得到,由此可以得到一系列方程,再加上所有网页的rank值之和为1的限制,使得方程可解。
矩阵形式:若 ,则 ,否则 。那么上述方程可以写成 。易知 是 特征值为1的特征向量。
如何求解 ?
幂迭代法
- 初始化
- 迭代
- 当 时停止
(马尔可夫过程(Markov processes))
上述幂迭代法存在问题:1.不收敛 2.收敛的结果不合理。原因是web图中存在
- dead end:一个点出度为0
- spider trap:一个子图的所有出边没有指向子图外的点
解决方法:Teleports 随机跳转:有 的概率,按照原来的策略走到相邻的节点;有 的概率以 的概率跳到每个节点,那么 ;;
Clustering 聚类
K-means
- 初始化,随机选取K个点作为聚类中心
- 迭代
- 将所有点分配到离它最近的聚类中心
- 用类中所有点的均值更新聚类中心
- 当点的分配或聚类中心不再变化时(两条件等价),停止
k-means是一种启发式的算法,需要初始化中心,有时候可能效果不理想,如何解决?
- 运行多次k-mean,选择error最小的
- 用其他策略进行初始化
K-means++
- 初始化
- 随机从数据点中选择一个作为一个聚类中心
- 计算每个样本与当前已有聚类中心最短距离(即与最近一个聚类中心的距离),用D(x)表示;这个值越大,表示被选取作为聚类中心的概率较大。依此选出下一个聚类中心
- 重复步骤2,直到选出k个聚类中心。
- 进行标准k-means算法
Mini-batch K-means
K-means优缺点:
- 优点:
- 简单,适用于规则的不相交的集群
- 收敛速度相对较快
- 相对高效和可扩展性
- 缺点:
- 需要提前指定K的值。需要一定的背景知识
- 可能收敛到局部最优
- 可能对噪声数据和异常值很敏感
- 不适用于非凸型集群
Clustering: Hierarchical Clustering 层次聚类
自底向上/凝聚 层次聚类
- 从每个集群中的单个点开始
- 确定最近的两个集群,合并它们
- 重复第2步,直到所有点都在一个集群中
可以用树状图来可视化
如何定义两个集群之间的距离?
- Single link(最近的点的距离):
- Complete link(最远的点的距离):
- Group average(平均距离):
- Centroid(中心距离):
- Ward(聚类中心方差):
优缺点:
- Single linkage的缺点:为了合并两个集群,只需要一对点较为接近,而不考虑所有其他的点。因此,集群可能过于分散,不够紧凑。
- Complete linkage的缺点:因为它的距离是基于点对之间最远情况的距离,所以一个点可以更接近其他集群中的点,而不是它自己的集群中的点。集群很紧凑,但距离不够远。
- Group average尝试达到平衡,它使用平均距离,因此集群往往相对紧凑和距离相对较远
- Group average的缺点:计算量比较大;聚类结果易受到距离计算方法的影响(例如曼哈顿距离改成欧几里得距离)
Lance-Williams算法
K-means vs Hierarchical clustering
- K-means
- 存储容量少 优
- 的计算时间 优
- 聚类结果对随机初始化敏感 缺
- 聚类的数量是预定义的 缺
- 层次聚类
- 确定的算法 优
- 可用树状图表示 优
- 只需要一个距离矩阵,量化观测结果之间的差异。(我们可以使用相异性度量来优雅地处理分类变量、缺失值等) 优
- 存储容量大,计算量大 缺
基于密度的聚类
core point:在该点的Eps-neighborhood距离内,有至少MinPts个点
border point:该点的Eps-neighborhood距离内,有少于MinPts个点,但它是core point的neighborhood
noise:不属于任何集群的点
DBSCAN:




优点:
- 抗噪声
- 可以处理不同形状和大小的集群
缺点:
- Eps和MinPts相互依赖,可能很难指定
- 对密度有变化的数据效果不好
- 对高维的数据效果不好
复杂度:
- 使用了所有点对的距离,但用高效的索引存储结构,可以使得neighborhood queries的时间复杂度在
- 整个算法的最优时间复杂度为
- neighborhood queries在高维数据情况下可能常数较大
- 内存不足会导致算法退化到
Linear Regression 线性回归
Linear Regression
Model:Linear Model:
Goodness of Function:Loss function:
Best Function:Gradient Descent
Model Selection
过拟合:过拟合是指相较有限的数据而言,模型参数过多或者结构过于复杂,且过于紧密或精确地匹配特定数据集,以致于无法良好地拟合其他数据或预测未来的观察结果的现象。(更复杂的模型在测试集上不一定能带来更好的效果)
正则化:。 越小意味着模型越平滑(smooth)。越大,正则项的惩罚效果就越强,正则化的约束就越强,模型的复杂度就越低,就越不考虑在训练集上的误差,越不容易过拟合。但容易欠拟合。
Bias and Variance 偏差和方差
bias:预测的function的均值与最佳的function的距离
variance:预测的function离散的程度
若模型在训练集上表现很差,意味着有较大的bias(欠拟合 underfitting);若模型在训练集上表现较好,但在测试集上表现较差,意味着有较大的variance(过拟合 overfitting)。对于较大的bias,应当使用较复杂的模型;对于较大的variance,应当使用更多训练数据或使用正则化。
模型选择:在bias和variance之间做权衡 N折交叉验证。
Gradient Decent 梯度下降
随机梯度下降和梯度下降的区别
随机梯度下降,加快训练过程,在每次更新时用一个样本来调整参数 。
Feature Scaling:特征缩放,将数据的不同变量或特征的范围进行标准化,e.g. 使得均值为0,方差和标准差为1。
Classification:Logistic Regression 分类:逻辑回归
逻辑回归
- model:
- loss function:
- 目标: 其中
令 for class1, for class2,可得
-
cross entropy
-
通过梯度下降确定 ,要计算梯度 。经计算可得 ,根据梯度下降的参数更新公式,可得 。(compare to linear regression)
Multi-class Classification
通过softmax层,将每个类别的结果通过 放大,然后规范化到(0,1)之间,且。然后要最小化cross entropy: 。其中,当 class i,那么 ,否则
多分类中的cross entropy
Deep Learning 深度学习
输入转化为向量,输入进网络,网络是各种函数的集合,网络中通过梯度下降更新参数,最后得到结果。
参考资料
https://blog.csdn.net/zhr1030635594/article/details/103918150?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170391299916800222816332%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=170391299916800222816332&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-103918150-null-null.142^v99^pc_search_result_base8&utm_term=%E5%B1%B1%E4%B8%9C%E5%A4%A7%E5%AD%A6%20%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_50213874/article/details/129511189?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%B1%B1%E4%B8%9C%E5%A4%A7%E5%AD%A6%20%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-6-129511189.142^v99^pc_search_result_base8&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_42809546/article/details/129011803?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170391299916800185835419%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=170391299916800185835419&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-10-129011803-null-null.142^v99^pc_search_result_base8&utm_term=%E5%B1%B1%E4%B8%9C%E5%A4%A7%E5%AD%A6%20%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2&spm=1018.2226.3001.4187
https://zhuanlan.zhihu.com/p/571530942
https://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/Logistic%20Regression%20(v3).pdf